
Protobuf vs JSON: The Compression Test That Changed My Mind
A few days back I was debating with a friend about REST vs gRPC in the context of client-server communication over the Internet. Where I was in favour of gRPC. During our debate, I jumped quickly to say protobuf are more optimised than JSON because they omit unwanted data. To which my friend replied that we don’t transfer plain JSON over the network anymore we always gzip them before sending them. He explained further, that all the optimisation that gRPC does is lost when we gzip the data. I couldn’t continue to argue my point because I didn’t have enough data to prove my point. Thus I decided to run an experiment to compare the size after gziping JSON vs Protobuf.
Since I was in the process of learning go language from scratch, I decided to use it for this experiment.
Code
var UserCounts = [...]int{1, 10, 100, 1000, 10000, 100000, 1000000}
func main() {
names := readUsername(usernamesFile)
usersList := UsersProto{
Users: []*UserProto{},
}
writer := tabwriter.NewWriter(os.Stdout, 0, 0, 1, ' ', tabwriter.Debug)
fmt.Fprintln(writer, "Users\tJSON Size\tGzipped JSON Size\tJSON Gzip size % \tProto Size\tGzipped Proto Size\tProto Gzip size %\tGzip Diff (JSON - Proto)")
for _, num := range UserCounts {
for i := 0; i < num; i++ {
name := names[rand.IntN(len(names))]
user := UserProto{
Name: name,
Age: rand.Int32N(91) + 10,
Email: fmt.Sprintf("%s@gmail.com", name),
}
usersList.Users = append(usersList.Users, &user)
}
jsonData, _ := json.Marshal(usersList)
protData, _ := proto.Marshal(&usersList)
gzippedProtoSize := gzipDataAndReturnSize(protData)
gzippedJsonSize := gzipDataAndReturnSize(jsonData)
jsonReduction := float64(gzippedJsonSize) / float64(len(jsonData)) * 100
protoReduction := float64(gzippedProtoSize) / float64(len(protData)) * 100
diff := gzippedJsonSize - gzippedProtoSize
fmt.Fprintf(writer, "%d\t%s\t%s\t%.0f%%\t%s\t%s\t%.0f%%\t%s\n",
num,
humanReadableSize(len(jsonData)),
humanReadableSize(gzippedJsonSize),
jsonReduction,
humanReadableSize(len(protData)),
humanReadableSize(gzippedProtoSize),
protoReduction,
humanReadableSize(diff),
)
}
writer.Flush()
}
// gzipDataAndReturnSize gzips the input data and return the len of the data
func gzipDataAndReturnSize(data []byte) int {
var buf bytes.Buffer
gw := gzip.NewWriter(&buf)
gw.Write(data)
gw.Close()
return buf.Len()
}
// humanReadableSize returns a human-readable size string.
// e.g. 1024 -> 1 KB
// e.g. 1048576 -> 1 MB
func humanReadableSize(bytes int) string {
}
// readUsername returns a array of dummy username
func readUsername(fileName string) []string {
}
I have intentionally kept only the important parts of the code and removed some not so important code. The full code can be found here.
In the above program, we are creating a list of user objects with fields name, age and email address. We pick a user name at random and use that in the name and email address fields. Once we have the data ready, we marshal them into JSON and proto, and then gzip them and print out the result.
We do this from 1 to 1000000 times with multiples of 10.
Result
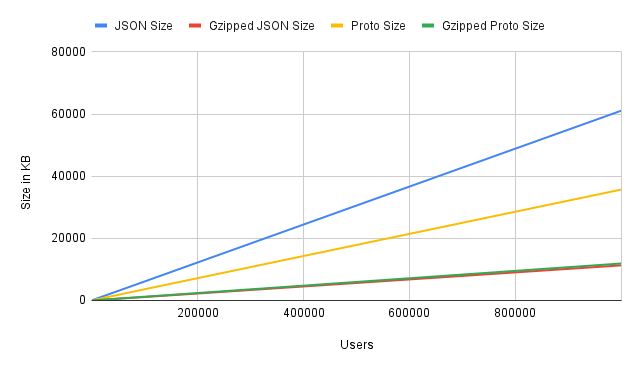
| Users | JSON Size | Gzipped JSON Size | JSON Gzip size % | Proto Size | Gzipped Proto Size | Proto Gzip size % | Gzip Diff (JSON - Proto) |
| 1 | 75B | 85B | 113% | 40B | 55B | 138% | 30B |
| 10 | 673B | 232B | 34% | 398B | 216B | 54% | 16B |
| 100 | 6.3KB | 1.4KB | 22% | 3.7KB | 1.4KB | 37% | 12B |
| 1000 | 62.5KB | 11.8KB | 19% | 36.5KB | 12.3KB | 34% | 542B |
| 10000 | 624.9KB | 115.7KB | 19% | 364.3KB | 121.7KB | 33% | -6.0KB |
| 100000 | 6.1MB | 1.1MB | 18% | 3.6MB | 1.2MB | 33% | -60.7KB |
| 1000000 | 61.1MB | 11.3MB | 18% | 35.7MB | 11.9MB | 33% | -603.8KB |
Observation
- When we have really small data, the gzipped size increases instead of decreasing. This is because, when data is gzipped it adds some additional metadata which will be used to decompress it. Here these metadata cause the size of the data to increase instead of decrease because the size of the data in itself is less.
- JSON compression is far more efficient than proto as the compressed size ratio is consistently better than protos gzipped data. EG: for 10 users the JSON size is 637B and gzipped size is 226B which is 35% of the original data. But in the same place for proto the gziped size is 37% of the original data.
- As the size of the data increases, the gziped sized of both proto and JSON remains consistent with minor difference.
The experiment was conducted for a list of Users. Which will have keys like “Name”, “Age” & “Email” repeated the same number of times as users. This must be making JSON more efficient. The real-world data will be different with limited key repetition thus the results could vary as well.
Conclusion
When we talk about REST vs gRPC in the context of client-server communication, where the client could be a mobile device which could face latency issues. The payload size advantage of gRPC making it faster doesn’t hold true because in today’s day and age gzip has become standard when sending data over the internet. However, there would be several other advantages that gRPC would provide over REST which is a topic for another day.